Pipeline
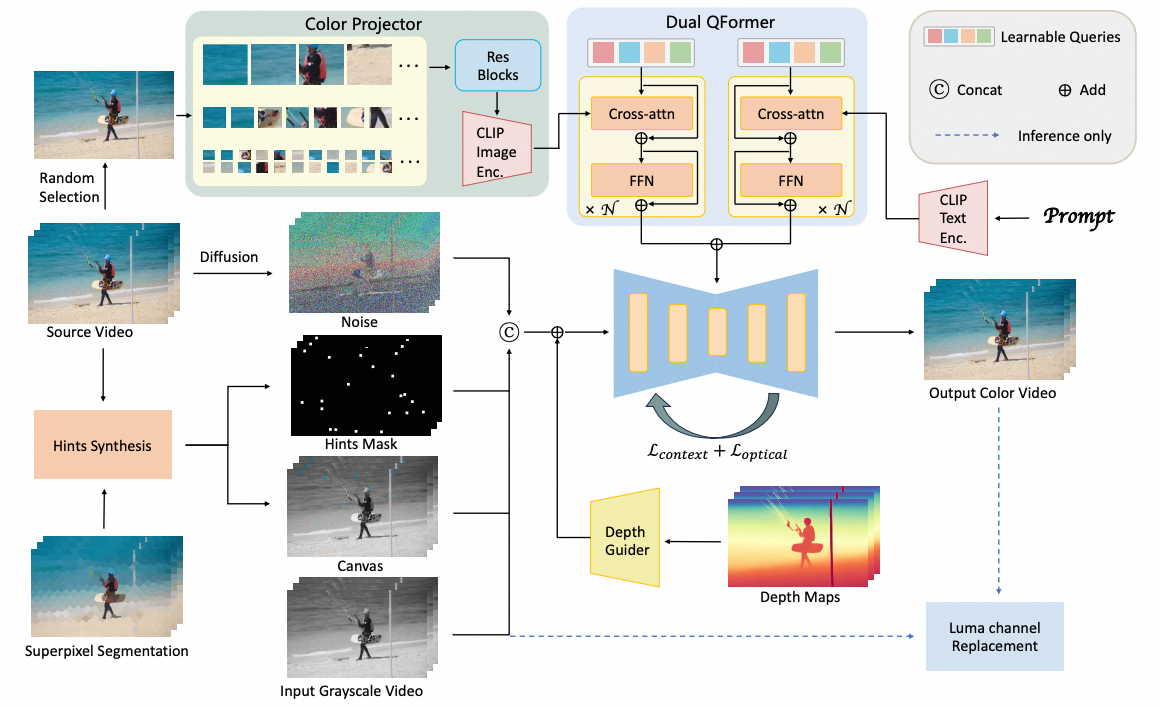
Video colorization aims to transform grayscale videos into vivid color representations while maintaining temporal consistency and structural integrity. Existing video colorization methods often suffer from color bleeding and lack comprehensive control, particularly under complex motion or diverse semantic cues. To this end, we introduce VanGogh, a unified multimodal diffusion-based framework for video colorization. VanGogh tackles these challenges using a Dual Qformer to align and fuse features from multiple modalities, complemented by a depth-guided generation process and an optical flow loss, which help reduce color overflow. Additionally, a color injection strategy and luma channel replacement are implemented to improve generalization and mitigate flickering artifacts. Thanks to this design, users can exercise both global and local control over the generation process, resulting in higher-quality colorized videos. Extensive qualitative and quantitative evaluations, and user studies, demonstrate that VanGogh achieves superior temporal consistency and color fidelity.
@misc{fang2025vangoghunifiedmultimodaldiffusionbased,
title={VanGogh: A Unified Multimodal Diffusion-based Framework for Video Colorization},
author={Zixun Fang and Zhiheng Liu and Kai Zhu and Yu Liu and Ka Leong Cheng and Wei Zhai and Yang Cao and Zheng-Jun Zha},
year={2025},
eprint={2501.09499},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2501.09499},
}